
Since launching the Aggregated Database (ADB) OneMusicAPI has been working away a lot more efficiently. Over the past couple of weeks OneMusicAPI has had to scale to two EC2 micro instances five times, a massive improvement on before when we were constantly running between two and four instances to keep up with demand.
The reason for this improvement is that ADB brings the data that OneMusicAPI used to query and stores it locally. Once a month we run an extract for each data source that is included in ADB; Wikipedia, Discogs and (soon to be released) MusicBrainz. This converts the source data into a common format. We then import this data into the ADB for OneMusicAPI to query.
So how does this look from a (very) high level architectural perspective? Here's how:
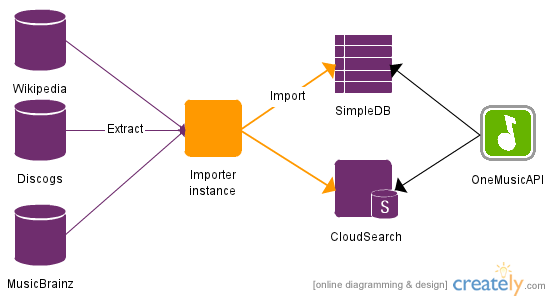
You can see the Importer instance performs the extract of the source databases and the import into the Aggregated Database. The Aggregated Database itself is stored in two Amazon data stores; SimpleDB and CloudSearch. SimpleDB holds all the data that is returned by OneMusicAPI. In addition, CloudSearch contains textual data that is available for natural language searching, so that's just things like album, artist and tag names.
On the other side, when you query OneMusicAPI, the ADB is, in turn, queried. How this works depends on the query. Initially, for "title based" queries (what I call queries using album titles, artist names and track names) CloudSearch is used at the first instance, and then the records discovered using CloudSearch are looked up on SimpleDB and all the data contained therein is returned.
For queries using more structured data, the plan is to have OneMusicAPI directly query SimpleDB directly, but the efficacy of this is to be established.
As I said, the MusicBrainz version of ADB is almost ready... stay tuned for updates!
Thanks to Vinoth Chandar who made the the image above available for sharing.